用 Q-Learning 走迷宫
这篇笔记用 Q-Learning 解一个 5×5 的网格迷宫:agent 从起点出发,反复尝试之后学会走最短路径。整个算法只是维护一张表加一条更新公式,不涉及神经网络,代码 60 行左右,只依赖 NumPy。
要解决的问题
迷宫长这样,S 是起点,G 是终点,# 是墙:
S..#.
.#.#.
.#...
..##.
#...G
agent 每步可以往上、下、左、右走一格,撞墙或出界就原地不动。目标是从 S 走到 G,步数越少越好,这个迷宫的最短路径是 8 步。
和前一篇的监督学习不同,这里没有任何标注数据——没人告诉 agent「在这个格子应该往下走」。它能得到的只有奖励:每走一步环境反馈一个数。agent 要靠反复尝试,从奖励里自己总结出该怎么走。
强化学习的基本设定
强化学习的框架是 agent 和环境之间的循环:agent 根据当前状态选一个动作,环境返回新状态和一个奖励,如此往复直到回合结束。
对应到迷宫里:
- 状态(state):agent 当前所在的格子,用坐标
(r, c)表示,一共 25 个。 - 动作(action):上、下、左、右,4 个。
- 奖励(reward):每走一步 -1。走到终点回合(episode)结束,从头再来。
- 回合(episode):从起点到终点的一次完整尝试。
奖励这么设计的意图:每步都要付出代价,累计奖励最大就等于步数最少。强化学习优化的目标只有累计奖励,想让 agent 做什么,都要靠奖励函数表达出来。
Q 表
Q-Learning 的核心是一张表 Q[s, a],含义是:在状态 s 做动作 a,之后一直按最优方式走,最终能拿到的累计奖励。这个例子里它是一个 (5, 5, 4) 的数组——25 个格子,每个格子 4 个动作各一个值。
如果这张表是准确的,最优策略就是现成的:每到一个格子,挑 Q 值最大的动作执行。问题变成怎么把这张表学准。
更新公式
Q 表初始全为 0,靠下面这一条公式在行走过程中逐步修正:
Q[s, a] += lr * (reward + gamma * max(Q[s']) - Q[s, a])
拆开看:agent 在状态 s 做了动作 a,实际拿到奖励 reward,落到了新状态 s'。此时对 Q[s, a] 有了一个新的估计:
target = reward + gamma * max(Q[s'])
即「这一步实际拿到的奖励,加上从新位置出发的最好前景」。这个 target 里有一份真实信息(reward 是环境实际给的),所以它比原来的 Q[s, a] 更靠谱一点。更新公式做的就是让 Q[s, a] 朝 target 挪一小步,lr 控制挪多少。用自己的估计修正自己的估计,只是掺了一步真实奖励,这个思路叫自举(bootstrapping);gamma 是折扣系数,控制未来奖励打多少折,这里取 1(不打折)。
终点不需要特殊处理:走到 G 回合就结束,Q[G] 从不会被更新,一直是 0——到了终点之后再没有奖励可拿,0 正好是对的。奖励信息随着一次次更新,从终点一格一格向外扩散,直到整张表收敛。
探索与利用
选动作时不能每次都挑当前 Q 值最大的。Q 表初始全 0,最先偶然走通的一条路会让沿途 Q 值率先升高,之后 agent 就一直沿这条路走,即使存在更短的路也永远不会被发现。
标准解法是 ε-greedy:以小概率 ε(这里 0.1)随机选动作(探索,explore),其余时间按 Q 表贪心(利用,exploit)。探索让每条路线都有机会被试到,避免早早锁死在次优路线上。严格的收敛在理论上还要求每个状态-动作组合被访问足够多次、学习率按一定条件衰减;这里为了代码简单,ε 和学习率都用固定值,对这个小问题足够了。
完整代码
import numpy as np
rng = np.random.default_rng(0)
MAZE = [
"S..#.",
".#.#.",
".#...",
"..##.",
"#...G",
]
N = 5
START, GOAL = (0, 0), (4, 4)
ACTIONS = [(-1, 0), (1, 0), (0, -1), (0, 1)] # 上、下、左、右
def step(state, action):
"""执行一步:返回 (新状态, 奖励)。撞墙或出界则原地不动。"""
r, c = state
dr, dc = ACTIONS[action]
nr, nc = r + dr, c + dc
if not (0 <= nr < N and 0 <= nc < N) or MAZE[nr][nc] == "#":
nr, nc = r, c
return (nr, nc), -1 # 每走一步奖励 -1
Q = np.zeros((N, N, 4)) # Q[r, c, a]:在格子 (r, c) 做动作 a 的价值
lr, gamma, eps = 0.1, 1.0, 0.1
for episode in range(500):
state = START
steps = 0
while state != GOAL and steps < 200:
r, c = state
if rng.random() < eps: # ε-greedy:小概率随机探索
action = rng.integers(4)
else: # 大概率按当前 Q 表贪心
action = int(np.argmax(Q[r, c]))
(nr, nc), reward = step(state, action)
target = reward + gamma * Q[nr, nc].max()
Q[r, c, action] += lr * (target - Q[r, c, action])
state = (nr, nc)
steps += 1
if episode == 0 or (episode + 1) % 100 == 0:
print(f"episode {episode + 1:3d} steps {steps}")
# 训练完后关掉探索,从起点按 Q 表贪心走一遍
path = [START]
state = START
while state != GOAL and len(path) < 50:
r, c = state
state, _ = step(state, int(np.argmax(Q[r, c])))
path.append(state)
print(f"\n贪心路径:{len(path) - 1} 步")
for r in range(N):
print("".join("*" if (r, c) in path and MAZE[r][c] == "." else MAZE[r][c] for c in range(N)))
print(f"\n起点的 Q 值:{np.round(Q[START], 2)}")
运行结果
episode 1 steps 72
episode 100 steps 13
episode 200 steps 12
episode 300 steps 10
episode 400 steps 8
episode 500 steps 8
贪心路径:8 步
S..#.
*#.#.
*#...
**##.
#***G
起点的 Q 值:[-8.49 -8. -8.69 -8. ]
第一回合乱走了 72 步,500 回合后贪心路径正好是最短的 8 步(* 标出了路线)。每回合的步数随训练下降:
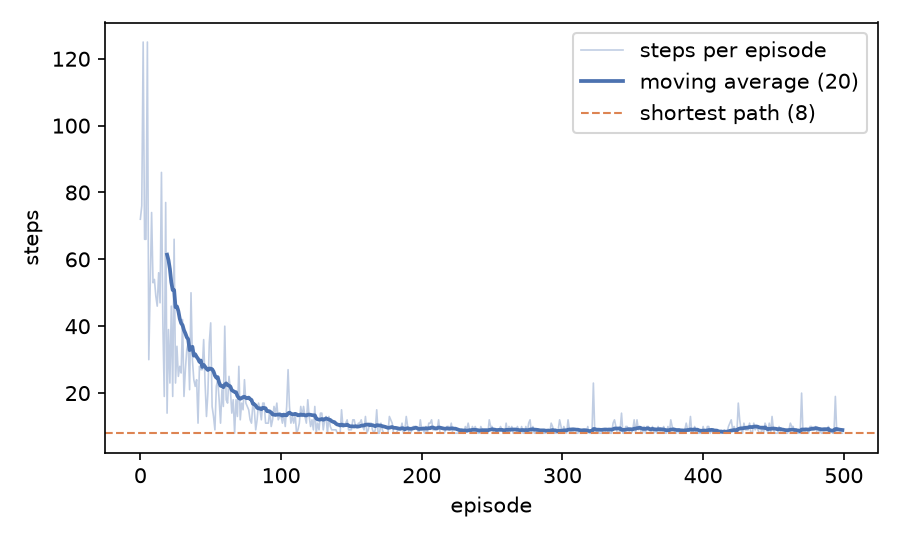
训练后期的毛刺来自 ε-greedy 的那 10% 随机动作,训练过程中它不会消失;贪心路径是关掉探索后走出来的,所以是稳定的 8 步。
起点的 Q 值也能对上:gamma 取 1、每步奖励 -1 时,Q[s, a] 收敛到「从这里出发还需要的步数」的相反数。四个值里「下」和「右」都是 -8.0,说明从起点往下和往右各有一条 8 步的最短路径,实际画一下确实如此;「上」和「左」是撞墙原地不动,白付一步代价,所以更差。完全收敛时这两个值应该是 -9(撞墙浪费一步,之后仍要走 8 步),现在是 -8.49 和 -8.69,方向已经学对、数值还没收敛到位——ε-greedy 下这两个明显亏的动作被试的次数少,估计自然更粗,再训练下去会慢慢逼近 -9。
几点说明
gamma取 1 在这里可行,是因为任务有终点、回合是有限的:随机探索下 agent 迟早能走到G(严格说是以概率 1,不是有限步内必然,所以代码里加了steps < 200的截断兜底)。对连续运行、没有明确终点的任务,gamma必须小于 1,否则累计奖励可能发散,Q 值不收敛。gamma越小 agent 越短视,只在乎眼前几步的奖励。np.argmax在平局时固定返回第一个,所以 Q 表全 0 的开局,贪心动作总是「上」。这里没造成问题:每步 -1 的奖励会立刻把试过的动作压成负值,平局马上被打破。更讲究的写法是平局时在并列最优的动作里随机挑一个,消除这个隐含的方向偏好。- 更新公式里用的是
max(Q[s'])——不管 agent 下一步实际做了什么(可能正在随机探索),更新时都假设之后按最优走。学的策略和行动的策略可以不同,这类算法叫 off-policy,Q-Learning 是最典型的一个。 - 表格法的适用范围止于「状态数得能装进一张表」。5×5 迷宫只有 25 个状态,围棋的状态数是天文数字,图像输入则根本没法枚举。解法是用一个函数来近似 Q 表——输入状态,输出各动作的 Q 值。用神经网络当这个函数,就是 DQN(Deep Q-Network),DeepMind 2013 年用它玩 Atari 游戏的那套方法。
- 奖励函数是任务定义本身,改它就是改任务。比如把撞墙的奖励改成 -5,agent 会更快学会不撞墙;但如果奖励设计得有漏洞,agent 也会忠实地钻漏洞,只优化数字而不完成你想要的事。
延伸
- Reinforcement Learning: An Introduction — Sutton & Barto:强化学习的经典教材,全书可以在官网免费阅读。这篇用到的表格方法在书的第一部分。
- Gymnasium:常用的强化学习环境库。里面的
FrozenLake和这里的迷宫基本是同一个问题,想接着练手可以从它开始。