用 NumPy 手写一个两层神经网络
这篇笔记用 NumPy 实现一个两层神经网络,对平面上的两类点做二分类。前向传播、交叉熵损失、反向传播、梯度下降都自己写,不依赖深度学习框架,完整代码 50 行左右。
要解决的问题
平面上撒两圈点:内圈是类 0,外环是类 1,各 200 个,半径带一点噪声。任务是给一个坐标 (x1, x2),判断它属于哪一类。
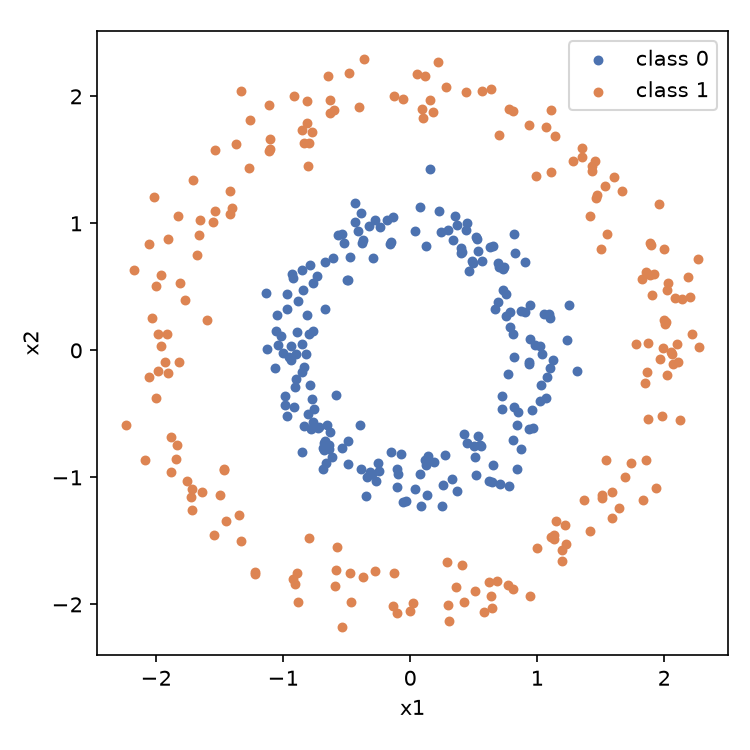
选这个数据是因为它线性不可分:类 0 被类 1 包在中间,画任何一条直线都分不开。只用原始坐标 (x1, x2) 做逻辑回归,决策边界就是一条直线,训练出来的准确率只会在随机水平附近。当然,手工加一个 x1^2 + x2^2 这样的径向特征,逻辑回归也能分开这份数据,但那等于人先替模型把特征变换做好了;神经网络的隐藏层做的正是这个变换,而且是从数据里学出来的,这正好能体现多出来的那层在干什么。
一个神经元
一个神经元做两件事:对输入加权求和,再过一个非线性函数(激活函数):
z = w1*x1 + w2*x2 + b # 加权求和,w 是权重,b 是偏置
h = max(z, 0) # 激活函数,这里用 ReLU
激活函数是必需的:如果没有它,不管叠多少层,展开之后都等价于单独一层——带偏置的线性变换(仿射变换)叠加起来还是仿射变换,决策边界仍然是一条直线,照样分不开两个圈。ReLU(负数归零、正数原样保留)是最常用的选择,导数也简单:正区间是 1,负区间是 0。
网络结构与前向传播
网络一共两层:8 个神经元的隐藏层(ReLU),加一个输出神经元(sigmoid,把任意实数压到 0 和 1 之间,当作「属于类 1」的概率)。
实现时不逐个神经元算,而是把 400 个样本堆成矩阵,一次算完。X 是 (400, 2) 的输入,y 是 (400, 1) 的标签:
z1 = X @ W1 + b1 # (400, 2) @ (2, 8) -> (400, 8)
h = np.maximum(z1, 0) # ReLU
z2 = h @ W2 + b2 # (400, 8) @ (8, 1) -> (400, 1)
a = 1 / (1 + np.exp(-z2)) # sigmoid,输出概率
前向传播就是这四行。要训练的参数是 W1 (2,8)、b1 (8,)、W2 (8,1)、b2 (1,),共 33 个数。
损失函数
训练需要一个数来衡量「预测得有多差」。二分类用二元交叉熵(binary cross-entropy):
loss = -np.mean(y * np.log(a) + (1 - y) * np.log(1 - a))
对单个样本看:标签是 1 时损失是 -log(a),预测概率 a 越接近 1 损失越小、接近 0 则趋于无穷大;标签是 0 时对称。相比「预测值减标签再平方」的均方误差,交叉熵对「自信但错误」的预测惩罚重得多,配合 sigmoid 求导之后的形式也更简洁(下一节能看到)。
反向传播
训练就是调这 33 个参数让 loss 变小。方法是梯度下降:算出 loss 对每个参数的偏导数(梯度指向 loss 增长最快的方向),然后往反方向挪一小步,重复几千次。
前向传播是一串函数套函数:X -> z1 -> h -> z2 -> a -> loss。按链式法则,loss 对链条上某个变量的导数,等于它到 loss 之间每一步局部导数的乘积。所以从 loss 出发倒着走一遍,边走边乘,就能拿到所有参数的梯度,这个过程就是反向传播。
下面推导会反复用到这些变量,先列一遍:
| 变量 | 含义 | 形状 |
|---|---|---|
X | 输入坐标 | (400, 2) |
y | 标签,0 或 1 | (400, 1) |
W1、b1 | 隐藏层的权重和偏置 | (2, 8)、(8,) |
z1 | 隐藏层的加权和 | (400, 8) |
h | 隐藏层输出(z1 过 ReLU) | (400, 8) |
W2、b2 | 输出层的权重和偏置 | (8, 1)、(1,) |
z2 | 输出层的加权和 | (400, 1) |
a | 预测概率(z2 过 sigmoid) | (400, 1) |
d 开头的变量表示 loss 对同名变量的梯度,形状和原变量相同:dz2 是 loss 对 z2 的梯度,形状 (400, 1);dW1 对应 W1,形状 (2, 8)。
第一步有个好用的结果:sigmoid 和交叉熵组合后,loss 对 z2 的导数化简完正好是「预测值减标签」:
dloss/dz2 = a - y
(推导:dloss/da = -y/a + (1-y)/(1-a),sigmoid 的导数是 da/dz2 = a(1-a),两者相乘,分母消掉。)
拿到 dz2 之后,剩下的每一步都是机械地套链式法则,和前向传播一一对应地倒回去:
dz2 = (a - y) / n # (400, 1),除以 n 是因为 loss 取了平均
dW2 = h.T @ dz2 # z2 = h @ W2 + b2,对 W2 求导剩下 h
db2 = dz2.sum(axis=0) # 对 b2 求导剩下 1,各样本的梯度求和
dh = dz2 @ W2.T # 误差穿过 W2 传回隐藏层
dz1 = dh * (z1 > 0) # 乘 ReLU 的导数:正区间 1,负区间 0
dW1 = X.T @ dz1 # 和 dW2 同理
db1 = dz1.sum(axis=0)
注意每个梯度的形状都和它对应的参数一样(dW1 是 (2,8),和 W1 相同),矩阵该转置还是该交换顺序,用形状对不对得上就能检查出来。最后更新参数:
W1 -= lr * dW1 # lr 是学习率,控制每步挪多远
完整代码
只依赖 NumPy,可以直接跑:
import numpy as np
rng = np.random.default_rng(42)
# 造数据:内圈是类 0,外环是类 1,各 200 个点
n_per_class = 200
r = np.concatenate([
rng.normal(1.0, 0.15, n_per_class), # 内圈半径
rng.normal(2.0, 0.15, n_per_class), # 外环半径
])
theta = rng.uniform(0, 2 * np.pi, 2 * n_per_class)
X = np.stack([r * np.cos(theta), r * np.sin(theta)], axis=1) # (400, 2)
y = np.concatenate([np.zeros(n_per_class), np.ones(n_per_class)]).reshape(-1, 1)
# 初始化参数:2 -> 8 -> 1
W1 = rng.normal(0, 0.5, (2, 8))
b1 = np.zeros(8)
W2 = rng.normal(0, 0.5, (8, 1))
b2 = np.zeros(1)
lr = 0.5
n = len(X)
for epoch in range(2001):
# 前向传播
z1 = X @ W1 + b1 # (400, 8)
h = np.maximum(z1, 0) # ReLU
z2 = h @ W2 + b2 # (400, 1)
a = 1 / (1 + np.exp(-z2)) # sigmoid,输出是「属于类 1」的概率
# 损失:二元交叉熵
loss = -np.mean(y * np.log(a) + (1 - y) * np.log(1 - a))
# 反向传播
dz2 = (a - y) / n # (400, 1)
dW2 = h.T @ dz2 # (8, 1)
db2 = dz2.sum(axis=0) # (1,)
dh = dz2 @ W2.T # (400, 8)
dz1 = dh * (z1 > 0) # ReLU 的导数:正区间 1,负区间 0
dW1 = X.T @ dz1 # (2, 8)
db1 = dz1.sum(axis=0) # (8,)
# 梯度下降
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
if epoch % 400 == 0:
acc = ((a > 0.5) == y).mean()
print(f"epoch {epoch:4d} loss {loss:.4f} acc {acc:.1%}")
运行输出(numpy 2.5.0):
epoch 0 loss 0.6674 acc 50.5%
epoch 400 loss 0.0185 acc 100.0%
epoch 800 loss 0.0082 acc 100.0%
epoch 1200 loss 0.0050 acc 100.0%
epoch 1600 loss 0.0036 acc 100.0%
epoch 2000 loss 0.0028 acc 100.0%
初始时准确率 50.5%(随机水平),几百轮之后训练集上的 400 个点全部分对。这里没有划分测试集,准确率是训练集上的——目的是演示训练过程,不算模型评估。
把训练好的网络在平面网格的每个点上算一遍输出概率,沿 0.5 那条等值线就能画出它学到的决策边界:
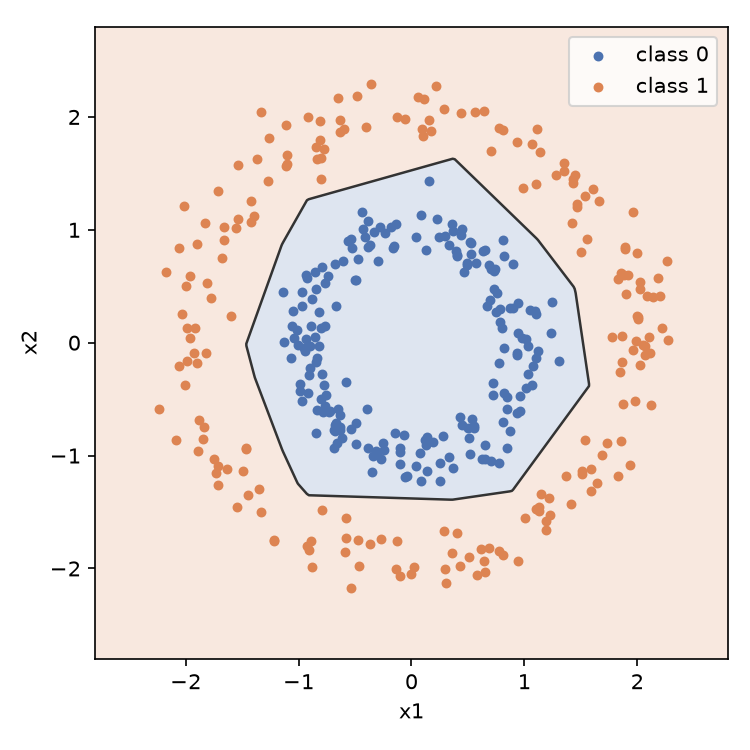
边界由直线段拼成,不是光滑曲线,这是 ReLU 网络的特点:每个隐藏神经元把平面折一刀,8 个神经元围出一个多边形。
附:画图代码
文中两张图的画法。接在训练代码后面运行,额外需要 matplotlib(pip install matplotlib);配色与文中略有差别,形状一致。
import matplotlib.pyplot as plt
mask0 = y.ravel() == 0
# 数据分布
plt.figure(figsize=(5, 5))
plt.scatter(X[mask0, 0], X[mask0, 1], s=14, label="class 0")
plt.scatter(X[~mask0, 0], X[~mask0, 1], s=14, label="class 1")
plt.gca().set_aspect("equal")
plt.legend()
plt.show()
# 决策边界:在平面网格上前向传播一遍,沿概率 0.5 的等值线画边界
gx, gy = np.meshgrid(np.linspace(-2.8, 2.8, 300), np.linspace(-2.8, 2.8, 300))
G = np.stack([gx.ravel(), gy.ravel()], axis=1) # (90000, 2)
gh = np.maximum(G @ W1 + b1, 0)
gp = (1 / (1 + np.exp(-(gh @ W2 + b2)))).reshape(gx.shape)
plt.figure(figsize=(5, 5))
plt.contourf(gx, gy, gp, levels=[0, 0.5, 1], alpha=0.2)
plt.contour(gx, gy, gp, levels=[0.5], colors="black", linewidths=1.2)
plt.scatter(X[mask0, 0], X[mask0, 1], s=14, label="class 0")
plt.scatter(X[~mask0, 0], X[~mask0, 1], s=14, label="class 1")
plt.gca().set_aspect("equal")
plt.legend()
plt.show()
几点说明
- 权重不能全初始化为 0。同一层的神经元如果初始值相同,收到的梯度也完全相同,永远学成一模一样,8 个神经元等于 1 个。随机初始化就是为了打破这种对称。偏置没有这个问题,可以从 0 开始。
- 隐藏层取 8 个神经元没有特别讲究,这个问题 4 个也够用,属于超参数——试出来的,不是算出来的。学习率 0.5 同理:太小收敛慢,太大 loss 会震荡甚至发散。
- 这里每轮用全部 400 个样本算梯度(full-batch)。数据大了这么算太贵,实际训练会每次随机抽一小批样本来估计梯度,也就是随机梯度下降(SGD)。
np.log(a)在a极接近 0 或 1 时会变成负无穷。这个例子规模小,训练过程中碰不到;正式的实现会先把a裁剪到[eps, 1-eps]区间(clip),或者改用把 sigmoid 和交叉熵合起来算的数值稳定形式(PyTorch 的BCEWithLogitsLoss就是后者)。- 用框架(PyTorch 等)和手写的差别主要在反向传播:框架记录前向的计算图后自动求导,不用再手推每层梯度。前向的写法和这里几乎一样。
延伸
- Neural Networks: Zero to Hero — Andrej Karpathy:视频课,从标量版的反向传播开始一路手写到 GPT。第一集的 micrograd 做的和这篇是同一件事,但拆解得更彻底。
- CS231n 课程笔记:斯坦福课程的配套笔记,反向传播、参数初始化、超参数怎么调这些主题都有系统的展开。